
Models trained on synthetic data produced by weak models outperform those with data from large models
"Bigger is not always better"

Who would have thought? Here’s yet another example that challenges common beliefs and practices in AI. Training a model on high-quality data generated by the biggest, strongest, and most expensive (SE) language model is often assumed to be optimal. However, as the recent (Oct 2024) paper below shows, this is not true at all.

The researchers demonstrate that a smaller and weaker model (WM) can generate better training data. In their own words:
“ Our findings reveal that models finetuned on WC-generated data consistently outperform those trained on SE-generated data across multiple benchmarks and multiple choices of WC and SE models. These results challenge the prevailing practice of relying on SE models for synthetic data generation, suggesting that WC may be the compute-optimal approach for training advanced LM reasoners.”
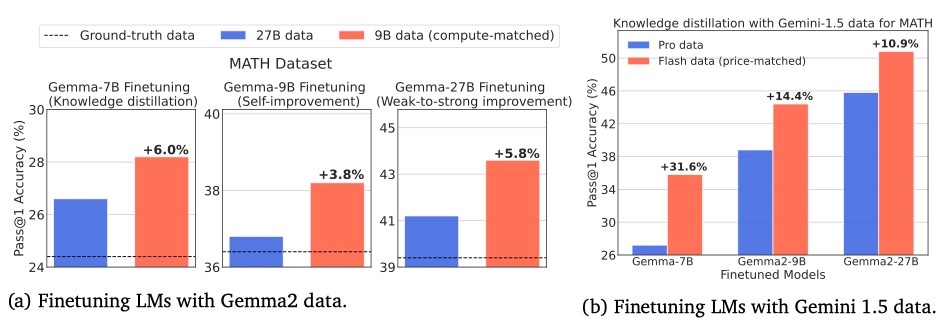
They finetuned Gemma-7B, 2-9B, and 2-27B on synthetic data collected from both a stronger but more expensive LM (Gemma2-27B) and a weaker but cheaper LM (Gemma2-9B) in a compute-matched setup for the MATH dataset. They found that training with Gemma2-9B data is more compute-optimal across diverse fine-tuning paradigms—knowledge distillation, self-improvement, and weak-to-strong improvement (i.e., using a weaker model to improve a stronger model).
The main reason is that they put a constraint on the budget, which means smaller models can generate more possible solutions than a SE. In a nutshell, more solutions cover a larger number of problems solved with more diverse solutions even if there are more false positives.
You can read the details in the paper, but this reminds me of an excellent article about a leaked Google internal email titled ‘We have no moat’ which essentially argues that “The uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI “ because the science goes much faster thanks to open-source projects that finetune smaller models. In their own words:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params what we struggle with at $10M and 540B. And they are doing so in weeks, not months.
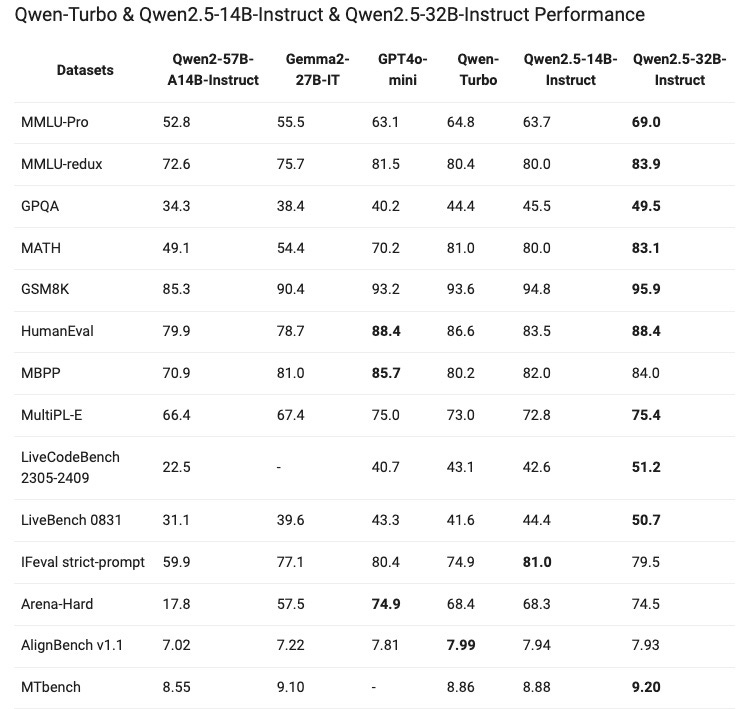
Alibaba has released Qwen with Questions, an open reasoning model that beats o1-preview. For example, Qwen 2.5 (QWQ), a 72-billion parameter model from Alibaba, outperforms GPT-4o at coding. This isn’t an isolated incident—it happens frequently that much smaller models outperform the latest GPT-4 model.

Beating GPT with a much smaller model in one category of reasoning is already an outstanding achievement. However, the 32-B parameter model goes even further—it beats (or equals) GPT-4o mini across ALL tests, as demonstrated in this benchmark.
As a parting gift, here’s a 12-lesson course to learn to build end-to-end production LLM systems using LLMOps.
Hi Devansh!
They put a constraint on the budget, which means smaller models can generate more possible solutions than a big LM. In a nutshell, more solutions cover a larger number of problems solved with more diverse solutions even if there are more false positives.
Did they give a reason why Smaller models would product better data?