
Vectorized convolutions
How to use Numpy meshgrids and einsum to compute all convolutions at once without any loop

This article is about convolutions between matrices, more specifically for Convolution Neural Networks, so, here’s a refresher on CNN's. Basically, you take a small matrix, called a kernel, or filter (in signal processing), say 3x3, you center it over every cell of a bigger matrix, like an image, and you compute the convolution between the kernel and the part of the image that the kernel covers (let’s call it the micro-image). This convolution is easy to do: multiply every corresponding pairs between the micro-image and the kernel, then add them all up. Let’s call it a “micro-convolution” to remind us that the real convolution has to be repeated on every every micro-image, of every input image.
To help visualize the process, here’s an animation that shows the micro-convolutions for an image of size 5 and a kernel of size 3.
[EDIT: I found these animations that also show padding and stride]
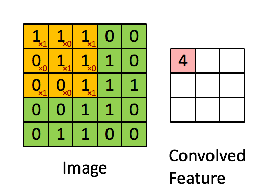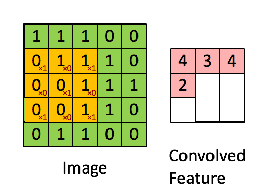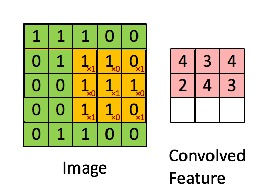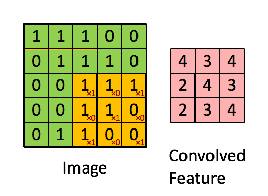
The article also introduces 2 more parameters: the stride and the padding. The padding is the size of the layers added around the image so the micro-convolutions are always between the kernel and a sub-matrix of the same size, which wouldn’t otherwise be possible when the kernel is near the borders and overshoots the image boundary. The stride is simply the step the micro-convolutions move around in the image. It is frequent to step over several cells at a time to reduce the size of the resulting convolution matrix.
Each micro-convolution can easily be calculated with a Numpy tensordot product. However, their number increases with the image size. The problem is even worse with CNN’s because, we have to do a convolution for every colour channel of every image in the dataset, and also for multiple kernels.
Of course, frameworks such as Pytorch do this for us using GPU’s, and CUDA cannot be beaten by any code. But this article is about learning how to use meshgrids and a fantastic Numpy function numpy.einsum, not getting the fastest code using a library, in which case we learn nothing.
As I’ll explain below, meshgrids + broadcasting will prepare all the kernel - image pairs at once (let’s call them ‘micro-pairs’), and numpy.einsum will compute all the micro-convolutions in parallel, for all micro-pairs in every input image. If you’ve never used it, I seriously advise you to learn it. After all, Einstein was using that notation for a reason…
Implementation with for loops
First, let’s look at the code with for loops to understand the task at hand.
def convolution(x, kernels, st):
'''
The forward pass
:param x: input matrix, with N*C*(H*W) images (C colours)
:param kernels: K*(kn,kn) kernels
:param st: stride
:return: resulting convolution between x and k
'''
N,C,H,W = x.shape
kn = kernels.shape[0]
pd = kn//2 # padding
hh, ww = (H - kn) // st + 1, (W - kn) // st + 1
# N,C,K,hh,ww is the size of the output
# we pad only the last 2 dimensions
dx = np.pad(x, ((0,0),(0,0),(pd,pd),(pd,pd))
for k in range(K):
for n in range(N):
for c in range(C):
for h in range(hh):
for w in range(ww):
sub_image = x[n,c,h*st:h*st+kn,w*st:w*st+kn]
dx[n,k,h,w] = numpy.tensordot(sub_image, kernels[k], axes=2)
return dx[:,:,pd:-pd,pd:-pd] # removes the paddingWe padded with zeros (default), but there are several padding strategies (see Numpy doc).
Micro-pairs preparation
So that’s 5 nested for loops. That’s where Numpy vectorization comes very handy. First, meshgrids calculate all the coordinates of all sub-images, so we can generate them once and cache them.
Why do we want to do that? Because one of the very nice features of Numpy vectorization is to access any number of cells by putting their coordinates in brackets. For instance, M[[1,5,2,1,3,5] (you can repeat indices) will create an array with M[1], M[5], M[2], M[1], M[3] and M[5] as if we go through all indices in sequence, except Numpy does that for us, at C speed. This means Numpy will execute all 5 for loops for us! Isn’t that neat? Meshgrids destroys the for loops, except we’ll still have to do the micro-convolutions (we’ll use numpy.einsum for that).
The indices can have several dimensions of course, so we can access chunks of a multi-dimensional matrix. That’s what we did when we defined micro-image. We took the nth image, the cth colour, and a chunk size (kn,kn) out of the corresponding matrix to get a micro-image of the same size as a kernel. The issue is that, in a CNN, the kernels change at every iteration, and also the images (if we use batches, which is guaranteed with large data sets) so we have to do it over and over. But, if we store the coordinates of every sub-image, we can access the micro-images for any input image using the same coordinates matrix.
What we are going to do here, is to calculate all the micro-images coordinates (let’s call them, you guessed it, micro-indices), so then we’ll be able to reference all of them with a single instruction. Notice that we don’t need a dimension for k since the micro-indices are the same for every kernel. Think about this for a minute! Vectorization will access all the micro-images in a 4D matrix in one instruction, ie x[micro-indices-matrix]. If you can visualize this, you can think in 4D. Congratulations!
The difficulty here is to avoid using for loops to create those indices. It wouldn’t be dramatic since we do it only once, but it will deprive you from understanding how we can use meshgrids + broadcast to generate them. In fact, we need a (kn,kn) matrix of indices for every (n,k,h,w) combinations, ie we will create a 6D matrix by broadcasting a 2D matrix into a 4D one. Can you still visualize that?
Let’s start small and first explain how meshgrids work. See the Numpy doc for more information. With Numpy.meshgrid and the shape of a matrix, say 2D (m x n), one can create all possible combinations of x and y coordinates. All positions 0 to m-1 will be reproduced horizontally in a (m x n) matrix, and all values 0 to n-1 vertically in a second matrix. Here’s an example:
x,y = np.meshgrid(range(2),range(3),indexing='ij') # gives 2 matrices
x = [[0, 0, 0], y = [[0, 1, 2]
[1, 1, 1]]) [0, 1, 2]]Notice that all x[i], y[j] correspond to the pair (i,j), so meshgrid has created all possible combinations for us to access all positions in a (m x n) matrix.
Now, if you use x and y on a matrix M, ie M[x,y], Numpy vectorization will create a new matrix M’ where M[i,j] is M[x[i,j], y[i,j]]. In other words, Numpy takes all combinations at x[i,j], y[i,j] from M to build M’.
If we give meshgrid 17 arguments corresponding to the dimensions of a 17D matrix, it will create 17 matrices (x1,…, x17) of indices that we can all feed into M[x1, x2, … x17] and vectorization will do all the work for us. This is how we eliminate the 4 loops (we don’t need the k loop as already pointed out) in one instruction. Super neat!
This is what we’re going to do here. We give 4 ranges over each dimensions, ie:
nn, cc, hh, ww = np.meshgrid(
np.arange(N), np.arange(C),
np.arange(0, H, st),
np.arange(0, W, st), indexing='ij')I can’t give a visual example for that. The best way to think about meshgrids is ‘it gives all combinations of all indices given as arguments, and puts each index in separate matrices’. It was obviously designed so the resulting matrices work with vectorization. Of course, if you do nothing else, M[nn,cc,hh,ww] will simply give… M. So we need to do something more.
If your brain is still working, now comes the hard part: broadcasting 2D meshgrids into 4D ones. Why do we need to do that? Because, as fantastic our 4D meshgrids are, they only give you the location of a single cell (which we will use as the upper left corner of every sub-image).
If you look into the code with the for loops, we don’t do x[n,c,h,w] (which is what x[4D meshgrids] would give, which corresponds to a single cell), but x[n,c, h*st:h*st+kn, w*st:w*st+kn]. We need to add two dimensions to take a chunk of size (kn,kn) at x[n,c,h,w], and it is THAT chunk that will be used to do the micro-convolution with a kernel.
[Btw, I’m using the word chunk, and not micro-image, because, now, we’re talking of indices of cells in the image, not their content. ]
For instance, if we had a kernel of size 2 (it has to be odd, but let’s make it simple), for vectorization to work, we would need 4 coordinates: [n,c,h,w,0,0], [n,c,h,0,1], [n,c,h,1,0] and [n,c,h,1,1]. In other words, we need to add all combinations of the kernel size in both directions to our 4D meshgrids. When you think ‘all combinations of’, you should think about meshgrids. That’s what they are for. In our case, we can easily create 2D meshgrids for the kernel as follows:
kh, kw = np.meshgrid(np.arange(kn), np.arange(kn), indexing='ij')What we want now, is to turn nn, cc, hh, ww into 6D matrices to be able to do x[nn, cc, hh, ww] to get the indices of (kn x kn) chunks, and let vectorization do its magic. How do we add dimensions to a matrix? Broadcasting! Here’s an example.

The Numpy doc says “The term broadcasting describes how NumPy treats arrays with different shapes during arithmetic operations. Subject to certain constraints, the smaller array is “broadcast” across the larger array so that they have compatible shapes. “ There are a few rules to respect. For instance, the arrays must have identical dimensions (but not the same number of dimensions) and one of them has to be 1.
Here’s a few examples from Numpy doc:

In short, broadcast stretches A (along the dimensions 1) to reach the shape B, in order to be able to perform operations, otherwise nothing would be possible. This is exactly what we want! We want to stretch every cell x[n,c,hh,ww] with the indices of kh and kw.
For that purpose, to respect the rules of broadcasting, we need to add two dimensions, and those are the ones that will be stretched. That’s easy to do using None as a placeholder for the future dimensions (one can also use np.newaxis, but I find it cumbersome). ‘All combinations’ means meshgrids, ‘stretching’ means broadcasting.
npatches = nn[:, :, :, :, None, None]
cpatches = cc[:, :, :, :, None, None]
hpatches = hh[:, :, :, :, None, None] + kh
wpatches = ww[:, :, :, :, None, None] + kw
micro_images_coords = dx[npatches, cpatches, hpatches, wpatches]
# we need to use the padded matrixIn other words, we added 2 dimensions to every 4D meshgrid, so the 2D meshgrids could ‘slide’ in it. It’s quite hard to visualize, but you can think of these 4 new matrices having the n,c,h,w coordinates in the first 4 dimensions, and all the coordinates of a kn x kn micro-image in the last 2. In other words, dx[npatches, cpatches, hpatches, wpatches] is a kn x kn chunk of an image, that will need to be convolved with the kernel. So, dx has the indices of ALL the micro-images that are going to be needed for the micro-convolutions of all images. So, we are now ready to use more vectorization to do all the micro-convolutions with the kernel at once.
That’s quite a feat. Are you still following? If you do, know the hardest part is behind us.
You may wonder ‘what are we going to do with 6D matrices full of coordinates?’. How will I get all my micro-convolutions done at every location of every image? It feels like we’ve made things more complex. That’s where another powerful function comes into play.
Einsum to the rescue
Numpy.einsum is the most powerful Numpy function imo. See Numpy doc and also this very good introduction about how to use it. It’s quite amazing honestly.
But there is a way to quickly grasp how it works. A typical instruction looks like the following. It takes a string as a first argument, which describes how the next two matrices have to be processed. The letters before the arrow describe the dimensions of those matrices, and the letters after the arrow, the dimension of the result we expect. Basically, einsum is ‘simply’ a ∑∑∑∑∑ over all the indices in the string except for the letters that end up after the arrow (those dimensions are kept). If you use the same letter for both matrices, it will multiply X[i] and Y[i]. Simple but powerful! It’s like writing maths. No wonder this notation comes from Einstein…
numpy.einsum('ABij,Cij -> ABC', X, Y, optimize=True)For instance, this instruction multiplies all cells at (i,j) in the AxB matrix with all cells at (i,j) in the C matrix, and sums them up, so those dimensions disappear. The other dimensions do not change so we’re left with an AxBxC matrix. I hope you see now where this is going, and why I added the coordinates of ‘chunks’ as 5th and 6th dimensions.
For our problem, the code is simply the following:
numpy.einsum('NChwij,KCij -> NKhw', micro_images_coords, kernels, optimize=True)Numpy will vectorize all those multiplications and additions in 6D, and will produce the K * N * hh * ww matrices we wanted. I couldn’t use hh and ww in the string since that would have meant h * h. Also, I had to use two different letters even if the kernel dimensions are identical, otherwise einsum would have taken the diagonal elements only. I used capital letters to make things clearer, they have no specific meaning otherwise.
Notice that C has disappeared. That’s because, in CNN, we add up the convolutions from the color channels for each image.
Numpy is not truly parallel though… Dask to the rescue
I wrote that code 2 years ago, and since then, I realized with horror that Numpy is not truly parallel. Super optimized, yes. Parallel, no. But, the Dask library is parallel, and they reproduced many Numpy functions. Thankfully einsum is one of them. So the final code is :
def convolution(x, kernels, st):
'''
The forward pass
:param x: input matrix, with N*C*(H*W) images (C colours)
:param kernel: K*(kn,kn) kernels
:param st: stride
:return: resulting convolution between x and k
'''
N,C,H,W = x.shape
kn = kernels.shape[0]
pd = kn//2 # padding
# h, w = (H - kn) // st + 1, (W - kn) // st + 1
# N,C,K,h,w is the size of the output
# we pad only the last 2 dimensions
dx = np.pad(x, ((0,0),(0,0),(pd,pd),(pd,pd))
nn, cc, hh, ww = np.meshgrid(
np.arange(N), np.arange(C),
np.arange(0, H, st),
np.arange(0, W, st), indexing='ij')
kh, kw = np.meshgrid(np.arange(kn), np.arange(kn), indexing='ij')
npatches = nn[:, :, :, :, None, None]
cpatches = cc[:, :, :, :, None, None]
hpatches = hh[:, :, :, :, None, None] + kh
wpatches = ww[:, :, :, :, None, None] + kw
micro_images_coords = dx[npatches, cpatches, hpatches, wpatches]
cnn = dask.array.einsum('NChwij,KCij -> NKhw',
micro_images_coords,
kernels, optimize=True)
return cnnComparison with Scipy.convolve2d
In the file in the repo, you’ll find a comparison between np.einsum and dask’ einsum. If we leave aside the time needed to create the 6D coordinates matrix, Dask is approx 50% faster.
There is also a comparison between Dask and Scipy convolve2d. Scipy is approx 4 times faster. But, as I said, this was not an exercise to optimize speed, but to learn vectorization.
However, I had to use 1 image and 1 kernel since Scipy can only process one 2D convolution at a time. So, if we need to process a huge amount of images and kernels, then we’ll have to use a for loop for Scipy, so it’s not as clear cut as it seems.
Also, this solution is more general and can be applied to your own algorithm. You won’t be able to use einsum anymore, but you could use numpy.vectorize (more in the next post).
I hope you enjoyed this article.
Let me know what you think.
BONUS QUESTIONS
Can you tell why we don’t need to remove the padding in the vectorized code?
The derivative of a convolution is a cross-correlation, which is calculated like a convolution except we use a flipped kernel as explained in the linked article. Maths never cease to amaze me. Can you modify the code to do that (without using numpy.flip of course) by modifying the meshgrids? Or the string in einsum?
Enjoy!
Btw, I found this article about the limits of vectorization with Python quite interesting.
Next time, I’ll show how we can use numpy.vectorize to vectorize any function to solve a Leetcode problem in an original way. Again, it won’t be the fastest solution, but it actually works like people visualize connected components, ie look for the boundaries and fill them, rather than scanning the matrix with 2 nested for loops. Stay tuned!
I just found this VERY COOL animation of CNN
https://animatedai.github.io
https://animatedai.github.io/media/convolution-animation-3x3-kernel.gif